介绍
免费和开源,高性能,分布式内存对象缓存系统。通过减轻数据库负载来加速动态Web应用程序, Memcached简单而强大。
可以选择的key值的hash算法: one_at_a_time、md5、crc16、crc32 、crc32a、fnv1_64、fnv1a_64、fnv1_32、fnv1a_32、hsieh、murmur、jenkins ,如果没选择,默认是fnv1a_64。
- 本质上就是一个内存Key-Value缓存
- 协议简单,使用文本行的协议
- 不支持数据持久化,服务器关闭后数据全部丢失
- 简洁强大,上手容易,便于快速开发
- 没有安全机制
Memcached设计理念
简单的键/值存储
服务器不关心您的数据是什么样的,只管数据存储服务端功能简单,很多逻辑依赖客户端实现
客户端专注如何选择读取或写入的服务器,以及无法联系服务器时要执行的操作。
服务器专注如何存储和管理何时清除或重用内存Memcached实例之间没有通信机制
每个命令的复杂度为 O(1)
慢速机器上的查询应该在1ms以下运行。高端服务器的吞吐量可以达到每秒数百万缓存自动清除机制
缓存失效机制
Memcached性能
Memcached性能的关键是硬件,内部实现是hash表,读写操作都是O(1)。硬件好,几百万的QPS都是没问题的。
最大连接数限
内部基于事件机制(类似JAVA NIO)所以这个限制和nio类似,只要内存、操作系统参数进行调整,轻松几十万。集群节点数量限制
理论是没限制的,但是节点越多,客户端需要建立的连接就会越多。
如果要存储的数据很多,优先考虑可以增加内存,成本太高的情况下,再增加节点。
服务器硬件需要
CPU要求
CPU占用率低,默认为4个工作线程内存要求
memcached内容存在内存里面,所有内存使用率高
建议memcached实例独占服务器,而不是混用。
建议每个memcached实例内存大小都是一致的,如果不一致则需要进行权重调整。网络要求
根据项目传输的内容来定,网络越大越好,虽然通常10M就够用了。
建议:项目往memcached传输的内容保持尽可能的小
Redis与Mamcached
| 功能点 | Mamcached | Redis |
|---|---|---|
| 操作线程 | 支持多线程 | 单线程 |
| 数据支持类型 | K/V类型,大V | 支持多种数据类型, V 512M限制 |
| 存储方式 | 内存中 | 支持AOF、 RDB持久化 |
| Key淘汰过期 | LRU | LRU、 LFU、 Random、 Noeviction、 TTL |
| 安全 | 没做安全控制 | 有安全控制 |
| 集群 | 本身没有支撑 | 主从、分片集群支持高 |
Memcached应用场景
- 数据查询缓存:将数据库中的数据加载到memcahced,提供程序的访问速度。
- 计数器的场景:通过incr/decr命令实现评论数量、点击数统计、操作次数等等场景。
- 乐观锁实现:例如计划任务多实例部署的场景下,通过CAS实现不重复执行。
- 防止重复处理: CAS命令
搭建
1 | yum install libevent‐devel |
命令
1 | # 启动 |
连接
memcached没有自己的客户端,通过telnet进行连接操作
1 | telnet localhost 11211 |
内存管理
启动 Memcached 时, -m指定内存大小,将信息保存到缓存中后才开始分配和保留物理内存。通过 Slab allocation 机制对内存进行管理。
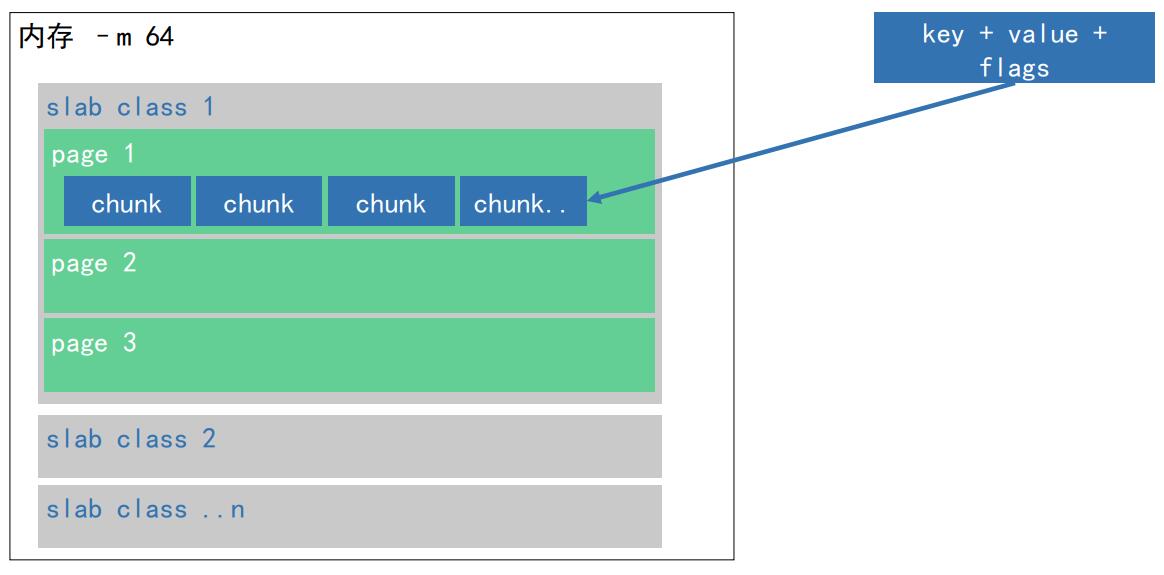
内存空间由slab classes构成,内存以slab page为单位去申请,分配到对应的slab class。
slab page :最大1兆,由1个或多个chunk组成
chunk:实际存储数据的单元
内存设计及管理
- Item
为键值数据的实际储存结构。 item主要由公共属性、数据部分两个部分组成。 - Chunk
由申请的连续内存块平均切分而成,用来存放Item数据,根据Item大小找到近似的Chunk。 - Slab
管理特定大小的 chunk 的集合。 Memcached每次默认分配的一个连续内存块为1M大小,它们被切分为不同大小的chunk。 - Hash table
Memcached的哈希表采用链接法实现。 hashtable被分成多个桶bucket,哈希冲突,通过h_next指针形成bucket下链接的单向链表。 - LUR
Memcached中每个slab中都维护了一个LRU链表,来组织该slab中已经被分配的item块,用于记录“最近最少使用”的item信息