Callable
Callable用于并发计算结果,然后将结果返回给调用线程,可以简化许多类型数值进行计算(其中部分结果需要同步计算)的编码工作,另外还可以用于运行那些返回状态码(用于指示线程成功完成)的线程。Callable是泛型接口
| 方法 |
描述 |
| Callable |
V指明了由任务返回的数据类型 |
| 方法 |
描述 |
| V call() |
定义希望执行的任务,在任务完成后返回结果。如果不能计算结果,那么call()方法必须抛出异常 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
class Sum implements Callable<Integer>
{
int stop;
Sum(int v)
{
stop = v;
}
public Integer call()
{
int sum = 0;
for(int i = 1; i <= stop; i++) {
sum += i;
}
return sum;
}
}
class Hypot implements Callable<Double>
{
double side1, side2;
Hypot(double s1, double s2)
{
this.side1 = s1;
this.side2 = s2;
}
public Double call()
{
return Math.sqrt(this.side1 * this.side1 + this.side2 * this.side2);
}
}
class Factorial implements Callable<Integer>
{
int stop;
Factorial(int v)
{
this.stop = v;
}
public Integer call()
{
int fact = 1;
for(int i = 2; i <= stop; i++) {
fact *= i;
}
return fact;
}
}
public class LearnCallable1
{
public static void main(String args[])
{
ExecutorService es = Executors.newFixedThreadPool(3);
Future<Integer> f1;
Future<Double> f2;
Future<Integer> f3;
System.out.println("Starting");
f1 = es.submit(new Sum(10));
f2 = es.submit(new Hypot(3, 4));
f3 = es.submit(new Factorial(5));
try {
System.out.println(f1.get());
System.out.println(f2.get());
System.out.println(f3.get());
} catch (InterruptedException exc) {
System.out.println(exc);
} catch (ExecutionException exc) {
System.out.println(exc);
}
es.isShutdown();
System.out.println("Done");
}
}
|
Future
Futrue是泛型接口,表示将由Callable对象返回的值。因为这个值是在将来的某个时间获取的,所以取名Future。
| 方法 |
描述 |
| V get() |
无限期地等待获得返回值 |
| V get(long wait, TimeUnit tu) |
运行使用wait指定超时时间,wait单位通过tu传递。 |
ForkJoinTask
ForkJoinTask是抽象类,用来定义能够被ForkJoinPool管理的任务。类型参数V指定了任务的结果类型。ForkJoinTask与Thread不同,ForkJoinTask表示任务的轻量级抽象,而不是执行线程。ForkJoinTask通过线程(由ForkJoinPool类型的线程池负责管理)来执行。通过这种机制,可以使用少量的实际线程来管理大量的任务。因此与线程相比,ForkJoinTask非常高效。
如果任务没有在ForkJoinPool内运行,则fork()或invoke()将使用公共池启动任务
| 方法 |
描述 |
| final ForkJoinTask fork() |
为调用任务的异步执行提交调用任务,这意味着调用fork()方法的线程将持续运行。fork()方法在调度好任务之后返回this |
| final V join() |
等待调用该方法的任务终止,任务结果被返回 |
| final V invoke() |
将并行(fork)和连接(join)操作合并到单个调用中,因此可以开始一个任务并等待该任务结束,方法返回回调任务的结果 |
| static void invokeAll(ForkJoinTask taskA, ForkJoinTask taskB) |
执行taskA和taskB,并等待所有指定的任务结束 |
| static void invokeAll(ForkJoinTask<?> … taskList) |
执行所有指定的任务,并等待所有指定任务结束 |
| boolean cancel(boolean interruptOK) |
取消任务,如果调用该方法的任务被取消,就返回true;如果任务已经结束或者不能取消,就返回false。interruptOK暂时不使用 |
| final boolean isCancelled() |
如果调用任务再结束之前已经取消,就返回true;否则返回false |
| final boolean isCompletedNormally() |
如果调用任务正常结束,即没有抛出异常,并且也没用通过cancel()方法调用来取消,就返回true,否则返回false |
| final boolean isCompletedAbnormally() |
如果调用任务是因为取消或是因为抛出异常而完成的,就返回true;否则返回false |
| void reinitialized() |
已完成的任务,使任务能够再次运行。 |
| static boolean inForkJoinPool() |
代码在任务内部执行,返回true;否则返回false |
| static int getQueuedTaskCount() |
获取调用线程的队列中任务的数量 |
| static int getSurplusQueuedTaskCount() |
获取调用线程的队列中任务数量超出池中其他线程任务数量的数目 |
| final void quietlyJoin() |
连接任务,但是不返回结果,也不抛出异常 |
| final void quietlyInvoke() |
调用任务,但是不返回结果,也不抛出异常 |
| final boolean isDone() |
任务完成了返回true;否则返回false |
RecursiveAction
RecursiAction是ForkJoinTask的子类,封装不返回值的任务。
| 方法 |
描述 |
| protected abstract void compute() |
放置任务运行的代码 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
class SqrtTransform extends RecursiveAction
{
final int seqThreshold = 1000;
double[] data;
int start, end;
SqrtTransform(double[] vals, int s, int e)
{
data = vals;
start = s;
end = e;
}
protected void compute()
{
if((end - start) < seqThreshold) {
for(int i = start; i < end; i++) {
data[i] = Math.sqrt(data[i]);
}
} else {
int middle = (start + end) / 2;
invokeAll(new SqrtTransform(data, start, middle), new SqrtTransform(data, middle, end));
}
}
}
public class LearnForkJoin1
{
public static void main(String args[])
{
ForkJoinPool fjp = new ForkJoinPool();
double[] nums = new double[100000];
for(int i = 0; i < nums.length; ++i) {
nums[i] = (double)i;
}
System.out.println("A portion of the original sequence:");
for(int i = 0; i < 10; i++) {
System.out.println(nums[i] + " ");
}
System.out.println("\n");
SqrtTransform task = new SqrtTransform(nums, 0, nums.length);
fjp.invoke(task);
System.out.println("A portion of the transformed sequence to four decimal places:");
for(int i = 0; i < 10; i++) {
System.out.format("%.4f", nums[i]);
}
System.out.println();
}
}
|
RecusiveTask
RecusiveTask是ForkJoinTask的子类,封装返回值的任务,结果类型是由V指定。
| 方法 |
描述 |
| protected abstract V compute() |
放置任务运行的代码,并返回任务结果 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
class Sum extends RecursiveTask<Double>
{
final int seqThresHold = 500;
double[] data;
int start, end;
Sum(double[] vals, int s, int e)
{
data = vals;
start = s;
end = e;
}
protected Double compute()
{
double sum = 0;
if(end - start < seqThresHold) {
for(int i = start; i < end; i++) {
sum += data[i];
}
} else {
int middle = (start + end) / 2;
Sum subTaskA = new Sum(data, start, middle);
Sum subTaskB = new Sum(data, middle, end);
subTaskA.fork();
subTaskB.fork();
sum = subTaskA.join() + subTaskB.join();
}
return sum;
}
}
public class LearnForkJoin2
{
public static void main(String args[])
{
ForkJoinPool fjp = new ForkJoinPool();
double[] nums = new double[5000];
for(int i = 0; i < nums.length; ++i) {
nums[i] = i * 10;
}
Sum task = new Sum(nums, 0, nums.length);
double summation = fjp.invoke(task);
System.out.println("Summation " + summation);
}
}
|
ForkJoinPool
ForkJoinPool管理ForkJoinTask的执行。ForkJoinPool使用一种称为工作挪用(work stealing)的方式来管理线程的执行。每个工作者线程维护一个任务队列。如果某个工作者线程的任务队列为空,这个工作者线程将从其他工作者线程取得任务,从而可以提高总效率,并且有助于维持负载均衡(因为系统中的其他进程会占用CPU时间,所以即使两个工作线程在他们各自的队列中具有相同的任务,也不能同在同一时间完成)。
ForkJoinPool使用守护线程(daemon thread)。当所有用户线程都终止时,守护线程自动终止。因此,不需要显示关闭ForkJoinPool。但是,公共池是例外,shutdown()方法对公共池不起作用。
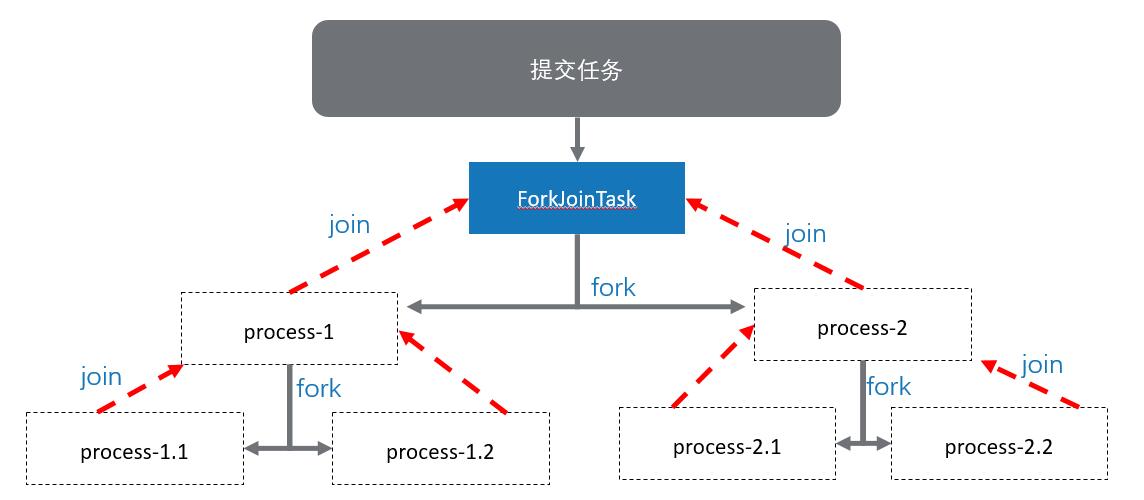
fork拆分执行过程
| 方法 |
描述 |
| ForkJoinPool() |
创建默认线程池,支持的并行级别等于可用处理器的数量 |
| ForkJoinPool(int pLevel) |
构造可以指定并行级别,值必须大于0并且不能超过实现的限制。 |
并行级别决定了能够并发执行的线程数量,因此,并行级别实际决定了能够同时执行的任务数量(当前,能够同时执行的任务数量不可能超过处理器的数量)。但是,并行级别没有限制线程池能够管理的任务数量,也就是说,ForkJoinPool能够管理大大超过其并行级别的任务数。此外,并行级别只是目标,而不是要确保的结果。
| 方法 |
描述 |
<T> T invoke(ForkJoinTask<T> task) |
开始由task指定的任务,并返回任务结果(调用代码会进行等待,知道invoke()方法返回为止)。 |
void execute(ForkJoinTask<?> task) |
开始由task指定的任务,但是调用代码不会等待任务完成,调用代码将继续异步执行 |
static ForkJoinPool commonPool() |
返回公共线程池的引用,公共池提供默认的并行级别,使用系统属性可以设置默认的并行级别 |
void shutdown() |
关闭线程池,当前活动的任务仍然会执行,但是不会启动新的任务 |
boolean isQuiescent() |
如果池中没有活动的线程,就返回true;否则返回false |
int getPoolSize() |
获取池中当前工作线程的数量 |
int getActiveThreadCount() |
获取池中当前活动线程的大概数量 |
List<Runnable> shutdownNow() |
立即停止池 |
boolean isShutdown() |
如果池已经关闭,就返回true;否则返回false |
boolean isTerminated() |
如果池已经关闭且任务都已经完成,返回true;否则返回false |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
| import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
public class LearnForkJoinPool {
static ArrayList<String> urls = new ArrayList<String>(){
{
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
add("http://www.baidu.com");
add("http://www.sina.com");
}
};
static ForkJoinPool forkJoinPool = new ForkJoinPool(3,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null,
true);
public static String doRequest(String url, int index){
return (index + "Kody ... test ... " + url + "\n");
}
public static void main(String args[]) throws ExecutionException, InterruptedException {
Job job = new Job(urls, 0, urls.size());
ForkJoinTask<String> forkjoinTask = forkJoinPool.submit(job);
String result = forkjoinTask.get();
System.out.println(result);
}
static class Job extends RecursiveTask<String> {
List<String> urls;
int start;
int end;
public Job(List<String> urls, int start, int end){
this.urls = urls;
this.start = start;
this.end = end;
}
protected String compute() {
int count = end -start;
if (count <=10){
String rsult = "";
for (int i=start; i< end;i++){
String response = doRequest(urls.get(i), i);
rsult +=response;
}
return rsult;
}else{
int x = (start + end) / 2;
Job job1 = new Job(urls, start, x);
job1.fork();
Job job2 = new Job(urls, x, end);
job2.fork();
String result = "";
result +=job1.join();
result += job2.join();
return result;
}
}
}
}
|
TimeUnit
TimeUnit是指定计时单位(或称粒度)的枚举,用于指明超时超时时间。
| 值 |
描述 |
| DAYS |
天 |
| HOURS |
小时 |
| MINUTES |
分 |
| SECONDS |
秒 |
| MICROSECONDS |
微妙 |
| MILLISECONDS |
毫秒 |
| NANOSECONDS |
纳秒 |
| 方法 |
描述 |
| long conver(long tval, TimeUnit tu) |
将tval转换指定单位并返回结果 |
| long toMicros(long tval) |
将tval转换成微秒并返回 |
| long toMillis(long tval) |
将tval转换成毫秒并返回 |
| long toNanos(long tval) |
将tval转换成纳秒并返回 |
| long toSeconds(long tval) |
将tval转成成秒并返回 |
| long toDays(long tval) |
将tval转换成天并返回 |
| long toHours(long tval) |
将tval转换成小时并返回 |
| long toMinutes(long tval) |
将tval转换成分钟并返回 |
| void sleep(long delay) |
暂停执行指定的延迟时间,延迟时间时根据枚举常量指定,sleep()方法调用会被转换成Thread.sleep()调用 |
| void timedJoin(Thread thrd, long delay) |
Trhead.join()的特殊版本,thrd暂停由delay指定的时间间隔 |
| void timedWait(Object obj, long delay) |
Object.wait()的特殊版本,obj等待由delay指定的时间间隔 |
Executor
线程执行器
| 方法 |
描述 |
| void execute(Runnable thread) |
启动指定的线程,thread指定的线程将被执行 |
Executors
线程池创建工具类
| 方法 |
描述 |
| newFixedThreadPool(int nThreads) |
创建一个固定大小、 任务队列容量无界的线程池。 核心线程数=最大线程数。 |
| newCachedThreadPool() |
创建的是一个大小无界的缓冲线程池。 它的任务队列是一个同步队列。 任务加入到池中, 如果 |
| 池中有空闲线程, 则用空闲线程执行, 如无则创建新线程执行。 池中的线程空闲超过60秒, 将被销毁释放。 线程数随任 |
|
| 务的多少变化。 适用于执行耗时较小的异步任务。 池的核心线程数=0 , 最大线程数= Integer.MAX_VALUE |
|
| newSingleThreadExecutor() |
只有一个线程来执行无界任务队列的单一线程池。 该线程池确保任务按加入的顺序一个一 |
| 个依次执行。 当唯一的线程因任务异常中止时, 将创建一个新的线程来继续执行后续的任务。 与newFixedThreadPool(1) |
|
| 的区别在于, 单一线程池的池大小在newSingleThreadExecutor方法中硬编码, 不能再改变的。 |
|
| newScheduledThreadPool(int corePoolSize) |
能定时执行任务的线程池。 该池的核心线程数由参数指定, 最大线程数= |
| Integer.MAX_VALUE |
|
ExcutorService
ExcutorService接口通过添加用于帮助管理和控制线程执行的方法,对Executor接口进行了扩展。 拓展了Callable 、 Future、 关闭方法
| 方法 |
描述 |
| void shutdown() |
停止调用ExcutorService对象 |
| Future submit(Callable task) |
提交一个返回值的任务,task是将在自己的线程中执行的Callable对象,结果通过Future类型的对象得以返回。 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class MyThread implements Runnable
{
String name;
CountDownLatch latch;
MyThread(CountDownLatch c, String n)
{
latch = c;
name = n;
new Thread(this);
}
public void run()
{
for(int i = 0; i < 5; i++) {
System.out.println(name + " : " + i);
latch.countDown();
}
}
}
public class LearnExec1
{
public static void main(String args[])
{
CountDownLatch cdl1 = new CountDownLatch(5);
CountDownLatch cdl2 = new CountDownLatch(5);
CountDownLatch cdl3 = new CountDownLatch(5);
CountDownLatch cdl4 = new CountDownLatch(5);
ExecutorService es = Executors.newFixedThreadPool(2);
System.out.println("Starting");
es.execute(new MyThread(cdl1, "A"));
es.execute(new MyThread(cdl2, "B"));
es.execute(new MyThread(cdl3, "C"));
es.execute(new MyThread(cdl4, "D"));
try {
cdl1.await();
cdl2.await();
cdl3.await();
cdl4.await();
} catch (InterruptedException exc) {
System.out.println(exc);
}
es.isShutdown();
System.out.println("Done");
}
}
|
ThreadPoolExector
基础、 标准的线程池实现
| 方法 |
描述 |
| public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue workQueue) |
corePoolSize指定核心线程数量;maximumPoolSize指定最大线程数量;keepAliveTime指定非核心线程之外创建的线程在闲置多少秒后被回收释放;unit指定回收的时间的单位;workQueue指定线程队列最大排队的任务数量,不传值表示无限; |
线程创建原理
- 是否达到核心线程数量? 没达到, 创建一个工作线程来执行任务。
- 工作队列是否已满? 没满, 则将新提交的任务存储在工作队列里。
- 是否达到线程池最大数量? 没达到, 则创建一个新的工作线程来执行任务。
- 最后, 执行拒绝策略来处理这个任务
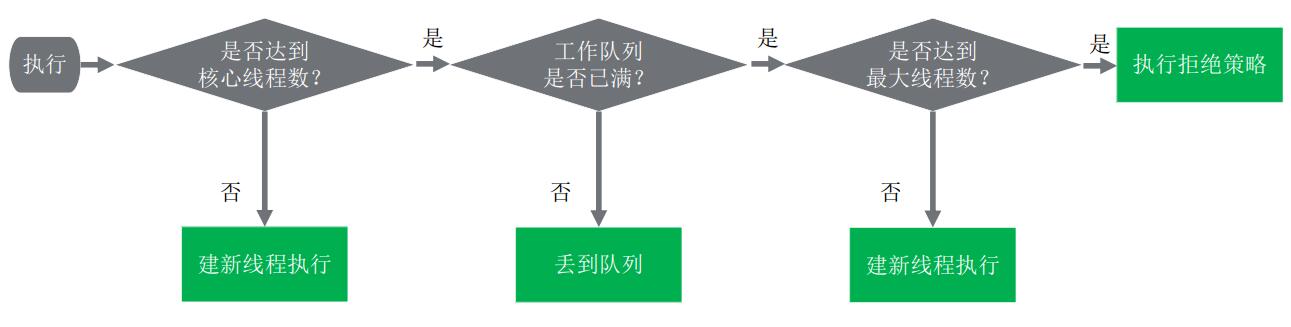
线程池线程创建原理
使用参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| package learn;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class LearnThread2 {
public static void main(String args[]){
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
5,
10,
5,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(100)
);
for (int i = 0; i < 30; i++) {
int n = i;
threadPoolExecutor.submit(new Runnable() {
@Override
public void run() {
try {
System.out.println("任务" + n +" 开始执行");
Thread.sleep(3000L);
System.err.println("任务" + n +" 执行结束");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
System.out.println("任务" + i + " 提交成功");
}
while(true){
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(">>> 线程数量:" + threadPoolExecutor.getPoolSize());
System.out.println(">>> 队列任务数量:" + threadPoolExecutor.getQueue().size());
}
}
}
|
ScheduledExecutorService
ScheduledExecutorService接口扩展了ExcutorService以支持线程调度。增加了定时任务相关的方法
| 方法 |
描述 |
| schedule(Callable callable, long delay, TimeUnit unit) |
创建并执行 一次性定时任务 |
| schedule(Runnable command, long delay, TimeUnit unit) |
创建并执行 一次性定时任务 |
| scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit) |
创建并执行一个周期性任务 |
| scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) |
创建并执行一个周期性任务 |
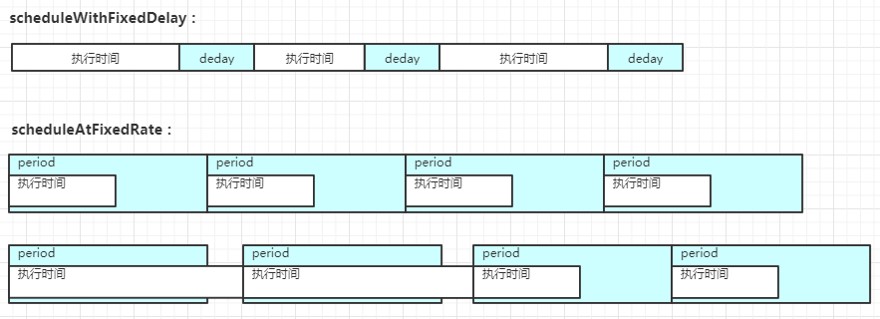
ScheduledExecutorService周期任务
ScheduledThreadPoolExecutor
继承了ThreadPoolExecutor, 实现了ScheduledExecutorService中相关定时任务的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.LockSupport;
public class LearnScheduledThreadPoolExector {
static ScheduledThreadPoolExecutor pool = new ScheduledThreadPoolExecutor(5);
public static void main(String[] args) throws Exception {
test3();
}
private static void test1() throws Exception {
Runnable cmd = new Runnable() {
@Override
public void run() {
try {
Thread.sleep(3000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务执行了。。。");
}
};
pool.schedule(cmd, 3, TimeUnit.SECONDS);
}
public static void test2(){
Runnable cmd = new Runnable() {
@Override
public void run() {
LockSupport.parkNanos(1000 * 1000 * 1000 * 1L);
System.out.println("任务执行,现在时间:" + System.currentTimeMillis());
}
};
pool.scheduleWithFixedDelay(cmd, 1000, 2000, TimeUnit.MILLISECONDS);
}
private static void test3() throws Exception {
Runnable cmd = new Runnable() {
@Override
public void run() {
LockSupport.parkNanos(1000 * 1000 * 1000 * 1L);
System.out.println("任务执行,现在时间:" + System.currentTimeMillis());
}
};
pool.scheduleAtFixedRate(cmd, 1000, 2000, TimeUnit.MILLISECONDS);
}
}
|
Exchanger
Exchanger用于简化两个线程之间的数据交换。在操作过程中,简单地进行等待,直到两个独立的线程调用exchange()方法为止,当发生这种情况时,交换线程提供的数据。Exchanger是泛型类。
| 方法 |
描述 |
| Exchanger |
V指定将要进行交换数据的类型 |
| 方法 |
描述 |
| V exchange(V objRef) |
objRef是对要交换的数据引用,从另外一个线程接收的数据返回 |
| V exchange(V objRef, long wait, TimeUnit tu) |
指定超时时间 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| import java.util.concurrent.Exchanger;
class MakeString implements Runnable
{
Exchanger<String> ex;
String str;
MakeString(Exchanger<String> c)
{
ex = c;
str = new String();
new Thread(this).start();
}
public void run()
{
char ch = 'A';
for(int i = 0; i < 3; i++) {
for(int j = 0; j < 5; j++) {
str += ch++;
}
try {
String strGet = ex.exchange(str);
System.out.println("from UsingString data:" + strGet);
} catch(InterruptedException exc) {
System.out.println(exc);
}
}
}
}
class UseString implements Runnable
{
Exchanger<String> ex;
String str;
UseString(Exchanger<String> c)
{
ex = c;
new Thread(this).start();
}
public void run()
{
for(int i = 0; i < 3; i ++) {
try {
String exStr = "UseString" + i;
str = ex.exchange(exStr);
System.out.println("==========from MakeString data:" + str);
} catch (InterruptedException exc) {
System.out.println(exc);
}
}
}
}
public class LearnExchanger1
{
public static void main(String args[])
{
Exchanger<String> exgr = new Exchanger<String>();
new UseString(exgr);
new MakeString(exgr);
}
}
|
Phaser
Phaser类的主要目的是允许表示一个或多个活动阶段的线程进行同步,与CyclicBarrier类似。通过Phaser可以定义等待特定阶段完成的同步对象。然后推进到下一阶段,再次进行等待,直到那一阶段完成为止。Phaser也可以用于同步只有一个阶段的情况。
| 方法 |
描述 |
| Phaser() |
注册party的数量为0的Phaser对象 |
| Phaser(int numParties) |
将注册party的数量设置为numParties |
术语“party”经常被应用于十月Phaser注册的对象,相当于线程的意思。通常phaser构造时的party数量为1,用于对应主线程。
| 方法 |
描述 |
| int register() |
注册party,返回注册party的阶段编号 |
| int arrive() |
通知完成当前阶段,返回当前阶段编号,如果Pahser对象已经终止,返回一个负值。array()方法不会挂起调用的线程,这意味着不会等待该阶段完成 |
| int arriveAndAwaitAdvance() |
通知当前阶段完成,并进行等待,直到所有注册party也完成该阶段为止 |
| int arriveAndDeregister() |
线程在到达时注销自身,返回当前阶段编号,如果Pahser对象已经终止,返回一个负值。它不等待该阶段完成,这个方法只能通过已经注册的party进行调用 |
| final int getPhase() |
获取当前阶段编号,第一个阶段是0,2阶段是1,等等。如果调用Phaser对象已经终止,就返回一个负值 |
| protected boolean onAdvance(int phase, int numParties) |
当推进阶段时,用于精确控制发送的操作。phase是当前阶段,numParties将包含已注册party的数量。为了终止Phaser,onAdvance()方法需要返回true。为了保持phaser活跃,onAdvance()方法必须范湖false。当没有主程的party时,onAdvance()方法的默认返回true,因此会终止Phaser |
| int getArrivedParties() |
获取已经到达的party数量 |
| int getUnarrivedParties() |
获取未到达的party数量 |
| boolean isTerminated() |
如果Phaser对象终止了返回true;否则返回false |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| import java.util.concurrent.Phaser;
class MyPhaser extends Phaser
{
int numPhases;
MyPhaser(int parties, int phaseCount)
{
super(parties);
numPhases = phaseCount - 1;
}
protected boolean onAdvance(int p, int regParties)
{
System.out.println("Phase " + p + " completed\n");
if(p == numPhases || regParties == 0) {
return true;
}
return false;
}
}
class MyThread implements Runnable
{
Phaser phsr;
String name;
MyThread(Phaser p, String m)
{
phsr = p;
name = m;
phsr.register();
new Thread(this).start();
}
public void run()
{
while(!phsr.isTerminated()) {
System.out.println("Thread " + name + " Beginning Phase " + phsr.getPhase());
phsr.arriveAndAwaitAdvance();
try {
Thread.sleep(10);
} catch (InterruptedException e) {
System.out.println(e);
}
}
}
}
public class LearnPhaser1
{
public static void main(String args[])
{
MyPhaser phsr = new MyPhaser(1, 4);
System.out.println("Starting\n");
new MyThread(phsr, "A");
new MyThread(phsr, "B");
new MyThread(phsr, "C");
new MyThread(phsr, "D");
while(!phsr.isTerminated()) {
phsr.arriveAndAwaitAdvance();
}
System.out.println("The Phaser is terminated");
}
}
|
CountDownLatch
CountDownLatch是等待计数倒计器,在计数不为0的时候,线程会一直阻塞等待,当计数器达到0时,打开锁存器。
| 方法 |
描述 |
| CountDownLatch(int num) |
num指定了为打开锁存器而必须发生的事件数量 |
| 方法 |
描述 |
| void await() |
直到与调用CountDownLatch对象关联的计数器达到0才结束等待 |
| boolean await(long wait, TimeUnit tu) |
只等待由wait指定的特定时间,wait表示的单位由tu指定。如果到达时间限制,返回false;如果倒计时达到0,将返回true |
| void countDown() |
递减与调用对象关联的技术器 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicLong;
public class LearnCountDownLatch {
static AtomicLong num = new AtomicLong(0);
public static void main(String[] args) throws InterruptedException {
CountDownLatch ctl = new CountDownLatch(10);
for (int i=0; i< 10; i++){
new Thread(){
@Override
public void run() {
for (int j=0; j< 10000000; j++){
num.getAndIncrement();
}
ctl.countDown();
}
}.start();
}
ctl.await();
System.out.println(num.get());
}
}
|
CyclicBarrier
CyclicBarrier是一个循环栅栏,用于在并发编程中,控制线程进行同时处理。
| 方法 |
描述 |
| CyclicBarrier(int numThreads) |
numThreads指定了在继续执行之前必须到达界限点的线程数量 |
| CyclicBarrier(int numThreads, Runnable action) |
action指定了到达界限点时将要执行的线程 |
| 方法 |
描述 |
| int await() |
进行等待,直到所有线程到达界限点位置,第1个线程的值等于等待线程数减1,最后一个线程返回0 |
| int await(long wait, TimeUnit tu) |
只等待由wait指定的时间,wait使用的单位由tu指定。第1个线程的值等于等待线程数减1,最后一个线程返回0 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.locks.LockSupport;
public class LearnCyclicBarrier {
public static void main(String[] args) {
CyclicBarrier barrier = new CyclicBarrier(4, ()->{
System.out.println("车人数满,上路...");
});
for (int i=0; i< 100; i++){
new Thread(){
@Override
public void run() {
try {
System.out.println("乘客上车..");
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
}.start();
LockSupport.parkNanos(1000 * 1000 * 1000L);
}
}
}
|
Semaphore
Semaphore实现了经典的信号量(实际就是一个共享锁)。信号量通过计数器控制对共享资源的访问。如果计数器大于0,访问是允许的;如果为0,访问是拒绝的。计数器计数允许访问共享资源的许可证,因此,为了访问资源,线程必须保证获取信号量的许可证。
通常,为了使用新号量,希望访问共享资源的线程尝试取得许可证。如果信号量的计数大于0,就表明线程取得许可证,这会导致信号量的计数减小;否则,线程会被阻塞,直到能够获取许可证为止。当线程不再需要访问共享资源时,释放许可证,从而增大信号量的计数。如果还有另外一个线程正在等待许可证,该线程将在这一刻取得许可证。
常用于限制可以访问某些资源(物理或逻辑的)线程数目。简单说,是一种用来控制并发量的共享锁。
| 方法 |
描述 |
| Semaphore(int num) |
num指定了初始的许可证计数大小,也就是任意时刻能够访问共享资源的线程数量 |
| Semaphore(int num, boolean how) |
how为true,可以确保等待线程以它们要求访问的顺序获得许可证 |
| 方法 |
描述 |
| void acquire() |
获得一个许可证,如果在调用时,无法取得许可证,就挂起调用线程,直到许可证可以获得为止 |
| void acquire(int num) |
获得num个许可证 |
| void release() |
释放一个许可证 |
| void release(int num) |
释放num个许可证 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import java.util.concurrent.Semaphore;
import java.util.concurrent.locks.LockSupport;
public class LearnSemaphore {
static Semaphore sp = new Semaphore(6);
public static void main(String[] args) {
for (int i=0; i<1000; i++){
new Thread(){
@Override
public void run() {
try {
sp.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
SimulateDbControl("localhost:3306");
sp.release();
}
}.start();
}
}
public static void SimulateDbControl(String uri) {
System.out.println("mysql ...:" + uri);
LockSupport.parkNanos(1000 * 1000 * 1000);
}
}
|