内置宏 通用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 源文件的文件名 __FILE__ # 该行代码所在的行号 __LINE__ # 源文件翻译到代码时的日期 __DATE__ # 源代码翻译到目的代码的时间 __TIME__ # ? __STDC__
window Linux 1 2 # 函数名 __PRETTY_FUNCTION__
main入口 main(argc, argv)
第一个参数(习惯上称为argc,用于参数计数)。
第二个参数(称为argv,用于参数向量)是一个指向字符串数组的指针,其中每个字符串对应一个参数。
各参数之间用空格隔开
argv[0]的值是启动该程序的程序名,所以argc的值至少为1。
enum 1 enum boolean { NO, YES};
1 2 3 4 5 6 enum escapes{ BELL = '\a' , BACKSPACE = '\b' , TAB = '\t' }
extern 变量使用
函数外定义的变量,默认是外部变量,加不加extern不重要。
函数内定义的变量,默认是局部变量,如果加上了extern,那么变量将会变成外部变量。
1 2 3 4 5 6 7 int b; void copy () int i; extern a; }
const const陷阱 1 2 3 4 5 type char * string ; const string str1;
define 1 2 3 4 5 6 7 8 9 #define STR(a) #a #define CAT(x,y) x##y int main (void ) int xy = 100 ; cout <<STR(ABCD)<<endl ; cout <<CAT(x, y)<<endl ; }
可变参数函数定义 1 2 3 4 5 #define debug(format, ...) fprintf (stderr, format, __VA_ARGS__) #define debug(format, args...) fprintf (stderr, format, args) #define debug(format, ...) fprintf (stderr, format, ## __VA_ARGS__)
带参数宏定义 1 #define MAX(a, b) (a)>(b)?(a):(b)
副作用 1 2 3 4 5 6 #define CALL_WITH_MAX(a, b) f((a) > (b) ? (a) : (b)) int a = 0 ;int b = 5 ;CALL_WITH_MAX(++a, b); CALL_WITH_MAX(++a, b+10 );
const与define区别
const定义的常量有类型,而#define定义的没有类型,编译可以对前者进行类型安全检查,而后者仅仅只是做简单替换
const定义的常量在编译时分配内存,而#define定义的常量是在预编译时进行替换,不分配内存。
作用域不同,const定义的常变量的作用域为该变量的作用域范围。而#define定义的常量作用域为它的定义点到程序结束,当然也可以在某个地方用#undef取消
建议
在高层次编程,建议使用const,enum替换#define
在低层次编程,#define是比较灵活的
typedef 定义新名字 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 typedef int Length;typedef char * String ;typedef struct tnode { int c; } Treenode; typedef struct tnode *Treeptr ;typedef int (*PFI) (char *, char *)
跨平台 用typedef来定义与平台无关的类型。
typedef 与 #define 区别 1 2 3 4 typedef char *pStr1;#define pStr2 char *; pStr1 s1, s2; pStr2 s3, s4;
register register 声明告诉编译器,它所声明的变量在程序中使用频率较高。其思想是,将register变量放在机器的寄存器中,这样可以使程序更小,执行速度更快。但编译器可以忽略此选项
进制 八进制
1 2 int c = '\011' ;int a = 011 ;
十六进制
1 2 int b1 = '\x11' ;int b2 = 0x11 ;
字段宽度 宽度限制 1 2 3 4 5 6 7 struct { unsinged int a : 1 ; } flags; flags.a = 10 ;
union 什么是union?
翻译过来说,就是共用体,或者也叫联合体。说到了union,也就是共用体,就不得不说一下struct了,当我们有如下的struct的定义时:
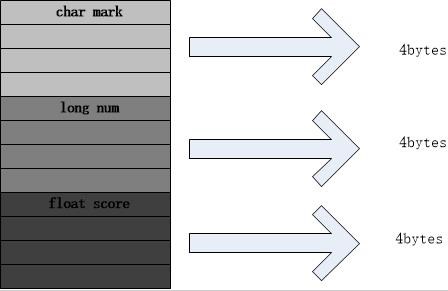
1 2 3 4 5 6 struct student { char mark; long num; float score; };
关于struct的内存结构,将就会像下图所示这样(在x86机器上演示)(内存对齐):
struct内存结构
sizeof(struct student)的值为12bytes。但是,当我们定义如下的union时,
1 2 3 4 5 6 union test{ char mark; long num; float score; };
sizeof(union test)的值为4。这为什么呢?这就是需要说的。 有的时候,我们需要几种不同类型的变量存在在同一段的内存空间中,就像上面的,我们需要将一个char类型的mark、一个long类型的num变量和一个float类型的score变量存放在同一个地址开始的内存单元中。上面的三个变量,char类型和long类型所占的内存字节数是不一样的,但是在union中,它们都是从同一个地址存放的,也就是使用的覆盖技术,这三个变量互相覆盖,而这种使几个不同的变量共占同一段内存的结构,称为“共用体”类型的结构。上面定义的union类型的结构如下:
union类型内存结构
上面也说了,sizeof(union test)的值为4。那为什么是4呢?大体上来说,结构体struct所占用的内存为各个成员的占用的内存之和(当然也需要考虑内存对齐 的问题了)。而对于union来说,在谭浩强的《C语言程序设计》中这么说:union变量所占用的内存长度等于最长的成员的内存长度。很显然,这是不对的,对于union所占用的内存大小,需要考虑内存对齐的问题。这就是为什么sizeof(union test)的值为4啦。
union使用 和struct一样,union只有先定义了共用体变量才能引用它。而且不能直接引用共用体变量,而只能引用共用体变量中的成员。就像我上面定义的union test。我们不能像下面这样直接引用union:
1 2 union test a;printf ("%d" , a);
这种直接引用是错误的,由于a的存储区有好几种类型,分别占不同长度的存储区,仅写共用体变量名a,这样使编译器无法确定究竟输出的哪一个成员的值。所以,应该写成下面这样:
同时,在使用union的时候,我们还需要注意以下的几点:
由于union中的所有成员起始地址都是一样的,所以&a.mark、&a.num和&a.score的值都是一样的。
union作为函数参数的时候要小心使用
union类型可以出现在结构体类型定义中,也可以定义union数组,反之,结构体也可以出现在union类型定义中,数组也可以作为union的成员。
union与对象 就单单C中的union,上面的总结已经够用了,但是,现在偏偏又有一个叫做C++的东西;当union遇到了C++中的对象时,一切又变得剪不断,理还乱。上面总结的union使用法则,在C++中依然适用。本来union本就是从C语言中的,如果我们在C++中继续按照C语言的那种方式使用union,那是没有问题的。如果我们在union中放一个类的对象呢?结果会怎么样?比如有以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> using namespace std ;class CA { int m_a; }; union Test{ CA a; double d; }; int main () return 0 ; }
可以看到,没有问题;如果我们在再类CA中添加了构造函数,或者添加析构函数,我们就会发现程序就会出现错误。由于union里面的东西共享内存,所以不能定义静态、引用类型的变量。由于在union里也不允许存放带有构造函数、析构函数和复制构造函数等的类的对象,但是可以存放对应的类对象指针。编译器无法保证类的构造函数和析构函数得到正确的调用,由此,就可能出现内存泄漏。所以,我们在C++中使用union时,尽量保持C语言中使用union的风格,尽量不要让union带有对象。
函数 边长参数函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <stdarg.h> void minprintf (char *fmt, ...) va_list ap; char *p, *sval; int ival; double dval; va_start(ap, fmt); for (p = fmt; *p; p++) { if (*p != '%' ) { putchar (*p); continue ; } switch (*++p) { case 'd' : ival = va_arg(ap, int ); printf ("%d" , ival); break ; case 'f' : dval = va_arg(ap, double ); printf ("%f" , dval); break ; case 's' : for (sval = va_arg(ap, char *); *sval; sval++) putchar (*sval); break ; default : putchar (*p); break ; } } va_end(ap); }
内联函数
当程序执行函数调用时,系统需要建立栈空间,保护现场,传递参数以及控制程序执行的转移等等。这些工作需要系统时间和空间的开销。有些情况下,函数本身功能简单,代码很短,但使用频率很高,程序频繁调用该函数所花的时间却很多,从而使得程序执行效率降低,CPU利用率不高。
为了提高效率,一个解决办法就是不使用函数,直接将函数的代码嵌入到程序中。但这个办法也有缺点,一是相同代码重复书写,二是程序可读性往往没有使用函数的好。
为了协调效率和可读性的矛盾,c++提供内联函数inline。
内联函数中,不能有循环语句、if语句或switch语句,否则,函数定义时即使有inline关键字,编译器也会把该函数作为非内联函数使用
当使用内联函数的时候,没有用到函数调用的开销,因为在编译的时候,内联函数会被展开,函数转换成代码的功能由编译器完成。
1 2 3 4 5 6 7 8 9 10 11 12 inline int max (int a, int b) return a > b ? a : b; } public : int max (int a, int b) { return a > b ? a : b; }
内联函数与宏定义区别
内联函数调用时,要求实参和形参的类型一致,会进行类型检查。另外内联函数会先对实参表达式进行求值,然后传递给形参。而宏调用时只用实参简单地替换形参。
内联函数是在编译的时候在调用的地方将代码展开的,而宏则是在预处理时进行替换的。
建议使用内联函数
namespace 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include "stdio.h" #include "TestNamespace.h" namespace AA{ void P () { printf ("AA::p\n" ); } } namespace BB{ void P () { printf ("BB::P\n" ); } } namespace CC{ void P () { printf ("CC::P\n" ); } } namespace DD{ void P () { printf ("DD::p\n" ); } } using namespace CC;int main () AA::P(); BB::P(); P(); using namespace DD; DD::P(); EE::P(); }
对象 栈对象
隐含调用构造函数(程序中没有显示调用),生存期结束的时候自动释放
堆对象
隐含调用构造函数(程序中没有显示调用),要手动释放
全局对象、静态全局对象
全局对象的构造先于main函数
已初始化的全局变量或静态全局对象存储于.data段中
未初始化的全局变量或静态全局对象存储于.bss段中(block started by symbol)
静态局部对象
已初始化的静态局部变量存储于.data段中
未初始化的静态局部变量存储于.bss段中
struct 内存对齐
内存对齐的问题主要存在于理解struct和union等复合结构在内存中的分布
编译器为每个“数据单元”安排在某个合适的位置上。
C、C++语言非常灵活,它允许你干涉“内存对齐”
数据项只能存储在地址是数据项大小的整数倍的内存位置上
为什么要内存对齐
如何对齐
第一个数据成员放在offset为0的位置
其它成员对齐min(sizeof(member)),#pragma pack所指定的值)的整数倍
整个结构体也要对齐,结构体总大小对齐至各个成员中最大对齐的整数倍
例子 对齐系数4 1 2 3 4 5 6 7 8 9 10 11 12 struct Student { char mark; char mark2; long num; float score; };
1 2 3 4 5 6 7 8 9 10 11 12 struct Student { char mark; long num; float score; char mark2; }; // 结构体大小为16 // mark : offset0 一共使用内存1 1 < 4 剩余空间3 // num : offset4 一共使用内存8 4 > 3 内存需要移动到新的对齐点 剩余空间0 // score : offset8 一共使用内存12 4 > 0 内存需要移动到新的对齐点 剩余空间0 // mark2 : offset12 一共使用内存16 1 > 0 内存需要移动到新的对齐点 剩余空间0
git
c++库大全https://github.com/fffaraz/awesome-cpp